

Como empresa de big data que utiliza docenas de fuentes de datos para construir la herramienta de análisis de datos de la industria musical, Soundcharts se enfrenta a metadatos corruptos cada día. A lo largo de los años, hemos desarrollado varios algoritmos que garantizan que nuestra base de datos sea lo más limpia posible, pero incluso ahora tenemos que mantener cierto mantenimiento manual. El equipo de Soundcharts aprendió de la peor manera lo corruptos que pueden estar los metadatos musicales — gestionando una base de datos de más de 2 millones de artistas.
Pero no se trata solo de nosotros. Lo cierto es que los problemas de metadatos causan mucho daño a la industria. Los metadatos comprometidos perjudican la experiencia de usuario en los servicios de streaming, recortan una parte de los ingresos de edición, roban a los compositores el crédito que merecen — y eso es solo el principio. Pero empecemos por lo básico:
¿Qué son los metadatos musicales?
Los metadatos musicales son los datos identificativos incrustados en un archivo de música, compuestos por cientos de etiquetas de texto que se adjuntan a través de contenedores de metadatos (siendo ID3v1 e ID3v2 con diferencia los más extendidos), detallando todo, desde el nombre del artista y la fecha de lanzamiento de la canción hasta los géneros asociados y los créditos de los compositores.
A primera vista, los metadatos pueden parecer algo insignificante, pero considera lo siguiente. Cada vez que un usuario busca una canción en Spotify; cada vez que BMI atribuye regalías de ejecución pública; cada vez que el algoritmo de Pandora pone en cola una canción — los metadatos están en juego. Son el aceite que hace girar los engranajes de la industria.
3 tipos de metadatos musicales
En general, los metadatos musicales pueden dividirse en tres tipos principales:
1. Metadatos descriptivos
Los metadatos descriptivos detallan el contenido de la grabación, con etiquetas de texto objetivo como el título de la canción, la fecha de lanzamiento, el número de pista, el artista intérprete, la portada, el género principal, etc. Tienen infinidad de aplicaciones. Los metadatos descriptivos se utilizan cada vez que alguien necesita consultar, organizar, clasificar o presentar la música — ya sea para crear una página de artista en Spotify, construir una biblioteca musical organizada o identificar y atribuir una emisión de radio.
Los problemas con los metadatos descriptivos son los más visibles para el usuario final. Si has usado algún servicio de streaming el tiempo suficiente, es probable que hayas encontrado errores derivados de descripciones corruptas. Piensa en canciones de varios artistas mezcladas en la misma página de artista en Spotify, páginas de artistas compuestos, nombres de canciones mal escritos, fechas de lanzamiento mezcladas — todo eso son consecuencias de metadatos descriptivos comprometidos. Estos problemas causan mucha confusión al consumidor — pero eso es solo la punta del iceberg.
2. Metadatos de titularidad/derechos de ejecución
Ya sea que hablemos de reproducciones digitales en streaming, emisiones de radio o sincronización cinematográfica, numerosas partes, desde artistas intérpretes hasta letristas, productores y compositores, compartirán los ingresos. De ahí la necesidad de metadatos de titularidad, que especifiquen los acuerdos contractuales detrás del lanzamiento a efectos del cálculo (y la distribución) de regalías. Los metadatos de titularidad existen para garantizar que cada una de las partes que participan en el proceso de creación musical sea remunerada adecuadamente.
Dada la compleja naturaleza de los repartos detrás de la mayoría de los temas (así como las diferencias legislativas en todo el mundo), dividir correctamente el dinero del consumidor no es poca cosa en sí mismo. Ahora bien, si añadimos metadatos faltantes o inconsistentes a la mezcla, el problema se vuelve diez veces más complicado. Los problemas con los metadatos de titularidad golpean donde más duele: un error humano aquí, un fallo en la base de datos allá — y un compositor puede perder decenas de miles de dólares.
Sin embargo, eso es solo parte del problema. Los créditos del artista también son la principal forma para que compositores, productores, músicos de sesión e ingenieros se hagan visibles para la industria musical, una especie de espacio de promoción «B2B». Los metadatos de titularidad corruptos roban a los músicos tanto dinero como crédito.
3. Metadatos de recomendación
Los dos primeros tipos de etiquetas de metadatos son objetivos — solo hay un nombre real de canción, y solo una lista de créditos de la canción. Los metadatos de recomendación son diferentes. En esencia, consisten en etiquetas subjetivas que pretenden reflejar el contenido de la grabación y describir cómo suena. Etiquetas de estado de ánimo, etiquetas de género generativas, puntuaciones de similitud entre canciones — los metadatos de recomendación se utilizan para establecer una conexión significativa entre pistas y potenciar los motores de recomendación.
Por supuesto, otros tipos de metadatos también pueden utilizarse para mejorar el descubrimiento musical. Las fechas de lanzamiento pueden ayudarte a detectar música de la misma era, y el nombre del productor coincidente puede ayudar a encontrar grabaciones similares. Sin embargo, la distinción crítica es el origen de los metadatos de recomendación.
El descubrimiento es un gran diferenciador entre los servicios de streaming. Por eso las etiquetas de metadatos de recomendación suelen ser datos propietarios que no circulan por la industria como los metadatos descriptivos y de titularidad. En cambio, cada plataforma tendrá su propio enfoque para la generación de metadatos de recomendación y su propia base de datos detrás del algoritmo de recomendación. Así, si los metadatos descriptivos y de titularidad se crean en el lado del artista, los metadatos de recomendación son producidos por los DSPs (o sus filiales).
Por ejemplo, Pandora adopta un enfoque de clasificación humana con su Music Genome Project. Spotify, por su parte, emplea una combinación de datos generados por los usuarios y etiquetas de metadatos de descubrimiento de The Echo Nest, producidas mediante una combinación de aprendizaje automático y curación humana. Si quieres echar un vistazo a la estructura de las etiquetas de metadatos de recomendación de The Echo Nest/Spotify y hacerte una idea general de cómo son los metadatos de recomendación, consulta el proyecto Organize Your Music.
Los metadatos de descubrimiento son el subconjunto de más rápido desarrollo del panorama general. La nueva tecnología está ampliando los límites del descubrimiento, exigiendo nuevas soluciones y enfoques para las recomendaciones.
Solo piensa en cómo los altavoces inteligentes cambiarán la forma en que accedemos y descubrimos la música. El consumo musical mediado por voz transforma a los usuarios de consultas de texto estructuradas a peticiones amorfas del tipo «Alexa, pon algo que me guste». Eso plantea un nuevo desafío a los motores de recomendación de las plataformas de streaming y los motores de búsqueda como Google. No bastará con encontrar canciones similares y generar colas de canciones tipo radio. Las plataformas de streaming tendrán que descubrir cuál es la mejor canción para reproducir a esa persona exacta en ese momento exacto. La forma en que aborden este desafío afectará el sustento de miles de artistas y profesionales de la música, dando forma al futuro de la industria musical durante años.

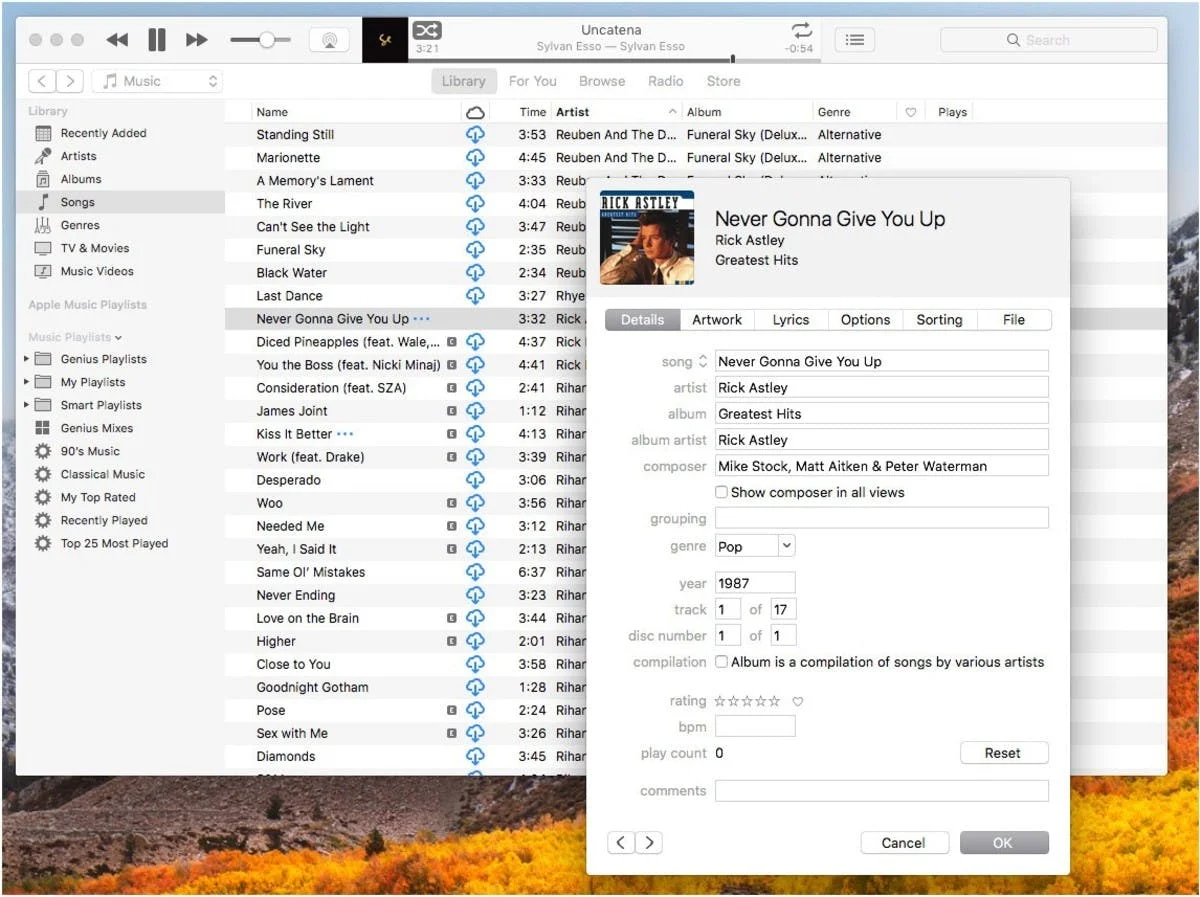
Errores de artistas compuestos en acción
Los problemas de los metadatos musicales
En este punto, un lector curioso podría preguntar: pero si los metadatos musicales son tan esenciales para el negocio musical, ¿por qué no los hemos arreglado todavía? ¿Por qué los compositores siguen perdiendo dinero y por qué la base de datos de iTunes está llena de errores de artistas compuestos? Bueno, el hecho es que el sistema de gestión de metadatos musicales siempre ha ido a remolque de los formatos de distribución de audio.
Por ejemplo, cuando el CD apareció por primera vez, no permitía ninguna etiqueta aparte de los datos descriptivos básicos — las cajas y los libretos de los CDs hacían las veces de adjunto de metadatos. Luego llegó Napster, y con él el caos. Los archivos MP3 (o FLAC) extraídos de CDs tenían prácticamente ningún metadato adjunto, y aún menos sobrevivían a las redes P2P, creando un enorme archivo de archivos de audio mal etiquetados.
1. Falta de estandarización de bases de datos
Luego, la música digital entró en escena y reemplazó a los formatos de grabación físicos. Todos los sectores de la industria comenzaron a almacenar e intercambiar datos, pero en aquella época nadie veía realmente la necesidad de estándares de metadatos unificados. Todas las tiendas digitales, sellos, editores, PROs y distribuidores crearon sus propias bases de datos — y los servicios de streaming siguieron sus pasos.
Hasta la fecha, no existe una estructura de base de datos unificada. Los metadatos fluyen a través de un entramado no estandarizado de bases de datos en toda la industria: de los sellos a los distribuidores, de los distribuidores a los DSPs, de los DSPs a las PROs, de las PROs a los editores.
Todas esas partes intercambian datos, pero las columnas y campos de sus bases de datos no siempre coinciden. Imagina que una base de datos recibe un valor en el campo «Corista» — cuando su propia columna correspondiente se llama «Coros». Los algoritmos no podrán hacer esa coincidencia (a menos que haya una regla específica para ello) y en el 99% de los casos, el crédito del corista simplemente se eliminará. Una gran parte de los metadatos se pierde en su camino a través de la cadena de datos musicales.
Además, para cada empresa musical, rara vez existe una única base de datos. En cambio, los datos se almacenan en múltiples bibliotecas musicales internas en diferentes formatos — y por eso necesitan ajustarse y validarse para establecer un intercambio adecuado con bases de datos externas.
El sistema actual de gestión de metadatos se creó en los albores de la música digital, cuando nadie sabía realmente cómo iba a evolucionar el panorama. Luego, la producción de datos creció exponencialmente. Ahora, 20.000 canciones se lanzan cada día y se empujan a través del intrincado sistema de bases de datos no del todo compatibles — generando miles de errores.
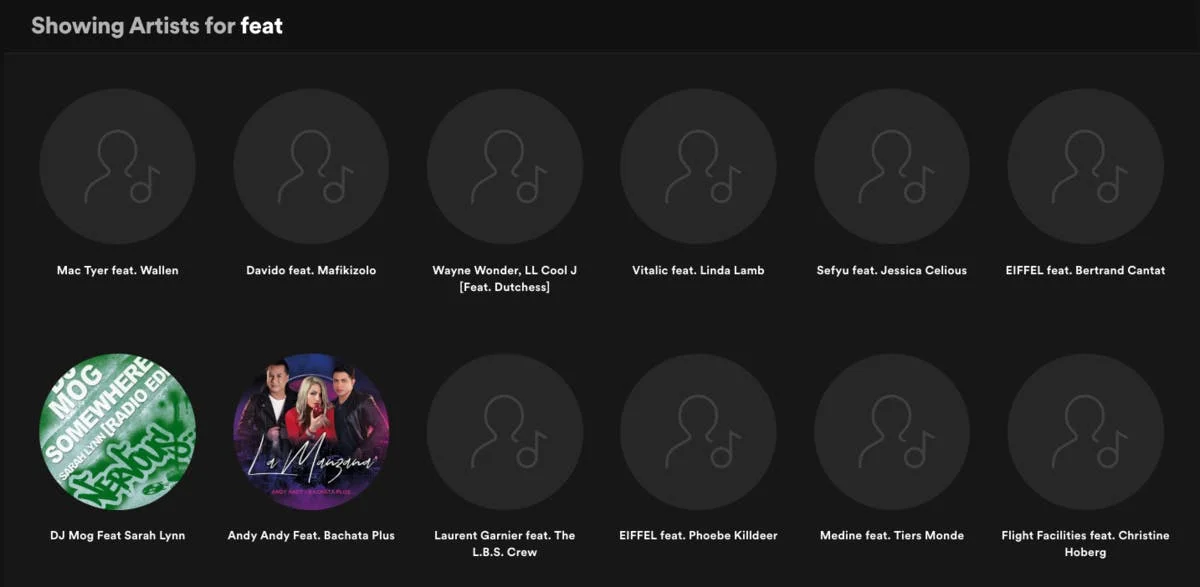
No te preocupes, Spotify tampoco va a la zaga
2. La multiplicidad de los datos musicales
El problema ni siquiera son las 20.000 canciones. También tiene que ver con el hecho de que esas canciones pueden ser diferentes variaciones de la misma obra musical. Pongámonos un poco técnicos por un momento. Cada canción se estructura a través de tres capas de abstracción:
- Una obra musical o composición — resultado del proceso creativo de compositores y productores, el pan y la mantequilla de los editores musicales.
- Una grabación sonora de la obra musical, producida e interpretada por artistas. La grabación sonora es una expresión particular de la obra musical.
- Un lanzamiento — una manifestación específica y empaquetada de la grabación sonora.
Así que todo comienza con compositores y autores creando una obra musical. Luego, esa composición puede expresarse de cien maneras diferentes — piensa en versiones cover, remixes, ediciones de radio, etc. Además, cada una de estas grabaciones sonoras puede lanzarse como single, parte de un álbum, parte de una edición deluxe, parte de una recopilación, etc.
Al final, una sola composición puede generar cientos (si no miles) de entidades de metadatos separadas, lo que complica enormemente el panorama. Las empresas musicales necesitan hacer coincidir todas esas diferentes capas de abstracción. Por ejemplo, si ASCAP recibe un informe de una emisión de radio para un lanzamiento específico, necesita vincularlo con la composición subyacente para localizar a los compositores.
3. Deficiencias del estándar de identificación musical
Uno podría pensar que la industria musical habría desarrollado un estándar para poder saber qué lanzamiento es versión de qué grabación sonora y hacer coincidir todas las capas de abstracción. Pues no del todo.
Actualmente, el estándar principal para la identificación musical en todos los formatos de archivo es el código ISRC — «un punto de referencia fijo cuando la grabación se utiliza en diferentes servicios, a través de fronteras o bajo diferentes acuerdos de licencia». Sin embargo, los códigos ISRC se asignan a las grabaciones sonoras — solo una de las capas de datos musicales.
Basándose únicamente en el ISRC, no podrás saber cuál es la obra musical original detrás de esa grabación concreta. No permite agregar las entradas a un nivel superior de abstracción para compilar todas las versiones de la misma pista o composición. Los límites del estándar ISRC hacen muy difícil para las empresas musicales corregir los metadatos rotos. Para dar sentido a los datos entrantes, los actores de la industria tienen que depender de las etiquetas de metadatos descriptivos para hacer coincidir el ISRC con otros IDs persistentes, como el UPC para lanzamientos o el ISWC para composiciones. Eso da lugar a todo tipo de errores, duplicados y conflictos en la cadena de datos musicales.
Ha habido varios intentos de crear una base de datos musical de referencia global, pero hasta la fecha no existe una fuente de verdad definitiva que permita resolver los conflictos de metadatos. Las bases de datos musicales públicas más destacadas son las plataformas de código abierto MusicBrainz y Discogs y el catálogo de códigos ISRC de la IFPI — pero, lamentablemente, todas están lejos de ser completas.
Las deficiencias del sistema de ID significan que las empresas musicales tienen que pasar por muchos obstáculos cada vez que encuentran un error de metadatos. Intentar conectar los puntos cruzando bases de datos llenas de inconsistencias en sí mismas es la rutina diaria de la gestión de datos musicales. Es decir, si a la empresa le importa lo suficiente.

La sección de créditos de canciones de Spotify pone de relieve los problemas con los metadatos de titularidad
4. Errores humanos
Por último, pero no por ello menos importante, tenemos lo que algunos llamarían el eslabón más débil de cualquier sistema. La mayoría de los metadatos descriptivos y de titularidad se crean y rellenan manualmente. Teniendo en cuenta la escala, eso inevitablemente lleva a todo tipo de errores tipográficos, nombres mal escritos, títulos, fechas de lanzamiento — o incluso datos directamente ausentes.
Toma, por ejemplo, los datos de titularidad. Los créditos de una canción pueden volverse extremadamente complicados, con docenas de compositores, ingenieros, músicos de sesión y productores trabajando en el mismo lanzamiento. Al mismo tiempo, los plazos no esperan — y por eso los acuerdos de titularidad y los repartos a menudo se pasan por alto cuando el equipo intenta sacar la nueva pista a tiempo. Con bastante frecuencia, los repartos se decidirán después del hecho — y una vez que la canción ya ha salido, es extremadamente difícil añadir o editar los metadatos.
Todos esos factores diferentes, desde los errores humanos y la incompatibilidad de bases de datos hasta los estándares de ID deficientes y la naturaleza multifacética de los derechos de autor musicales, crean la sombría realidad de los metadatos musicales modernos. La columna vertebral de la industria musical es quizás el mayor desastre que el mundo de los datos ha visto jamás.
¿Cómo arreglamos los metadatos?
La situación actual, en la que todos pierden, está pidiendo un cambio a gritos. Unos metadatos limpios podrían ayudar a un músico de sesión a conseguir el próximo trabajo, pagar el alquiler del compositor, optimizar la experiencia de usuario en los servicios de streaming — y ahorrar millones a la industria en el camino. Sin embargo, no hay una respuesta clara sobre cómo solucionar el problema. Aunque tampoco hay que ser demasiado pesimista — hay varias empresas, iniciativas y organizaciones trabajando hacia un sistema mejor.
Soluciones de limpieza, gestión y administración de metadatos
El primer tipo de empresas de metadatos trabaja en la creación de bases de datos musicales y luego limpia, repara y amplía las etiquetas de metadatos. Empresas como Gracenote, Musicstory y, hasta cierto punto, The Echo Nest son los proveedores de metadatos de varios DSPs en toda la industria. Estas empresas se ocupan principalmente de los metadatos descriptivos y de recomendación. Utilizan una combinación de algoritmos de limpieza de metadatos y tecnología de reconocimiento de audio para potenciar la búsqueda, las playlists y el descubrimiento musical, garantizando al mismo tiempo una visualización correcta para las tiendas digitales.
En el otro lado de la cadena de datos, empresas como VivaData, Exploration y TuneRegistry están desarrollando soluciones para sellos independientes, editores y artistas. Su objetivo es ayudar a las empresas musicales con la gestión interna de metadatos, auditar las bases de datos existentes en busca de metadatos incompletos/corruptos y agilizar los flujos de datos salientes en la raíz misma del flujo de datos musicales.
Sin embargo, todas esas empresas están tratando los síntomas, no la causa del problema. No me malinterpretes, es fundamental intentar limpiar el desorden existente — pero eso no resolverá los problemas sistemáticos.
Nuevos estándares de bases de datos
Quizás el cambio más significativo vendría si nos aseguramos de que las bases de datos en toda la industria musical son totalmente compatibles. Sin embargo, la optimización del sistema de metadatos a escala de la industria requeriría coordinación entre todas las partes del negocio, lo cual no es tarea fácil.
El actor más visible en ese espacio es DDEX, una organización internacional que desarrolla y promueve nuevos estándares y protocolos de datos para optimizar la cadena de datos digital. Ofreciendo soluciones que cubren la totalidad del sistema de datos musicales, DDEX ya ha logrado avances significativos, contando con algunos de los nombres más importantes de la industria entre sus miembros. Los estándares DDEX pretenden facilitar la gestión de metadatos en el estudio, armonizar las transferencias de metadatos entre propietarios de contenido y DSPs y mucho más.
En esencia, el objetivo de la organización es construir una tubería de ciclo completo para los metadatos musicales, desde el punto en que se crean hasta el destino final. Implementar protocolos de intercambio estándar para los metadatos musicales podría limpiar potencialmente la industria de miles de errores de incompatibilidad. Sin embargo, aunque las iniciativas de DDEX pueden ayudar a desarrollar un mejor sistema, eso no resolverá todos los problemas de metadatos.
Sin querer sonar a tópico, cuando se trata de arreglar los metadatos, debes empezar por ti mismo. Una parte considerable de los errores se debe a la falta de concienciación entre los profesionales de la música — lo que es, en parte, la razón por la que escribimos este artículo.
¿Qué puedes hacer para ayudar a arreglar los metadatos musicales?
La regla general es asegurarse de que todos los metadatos de la canción estén correctamente rellenados y verificados antes del lanzamiento de la canción (o el álbum). Eso no es tan fácil como parece. Aquí tienes algunos consejos para asegurarte de no contribuir al montón de metadatos musicales corruptos:
1. Lleva un registro de los metadatos desde el principio
Cada canción puede tener docenas (si no cientos) de colaboradores, y por eso llevar un registro de todas las personas que trabajan en el lanzamiento puede desmadrarse muy rápido. Por eso es crucial llevar un registro de los créditos de la canción desde el momento en que haya más de una persona implicada en el proyecto.
Sound Credit y los Creator Credits de Auddly (la función aún estaba en desarrollo en el momento de escribir este artículo) pueden ayudarte en esto. Estas soluciones permiten incrustar créditos y otros metadatos directamente en los archivos DAW que circulan por el estudio. De esa manera puedes mantener los créditos en el mismo lugar y mantener un registro consistente de todas las versiones de canciones y colaboradores en todos los archivos musicales.
2. Finaliza los acuerdos y define los repartos antes de que la canción salga del estudio
Los derechos musicales tienden a complicarse mucho, y la prisa por cumplir con el plazo de lanzamiento a menudo puede dejar los metadatos de titularidad incompletos. Sin embargo, unos metadatos de titularidad incompletos pueden significar que algunos, o incluso todos, los colaboradores no reciban ningún pago. Para facilitar el lado contractual de las cosas, considera usar Splits, una aplicación gratuita creada para rastrear y gestionar los colaboradores de una canción y, bueno... los repartos.
3. Asegúrate de que los metadatos estén rellenados correctamente
Los errores tipográficos pueden parecer insignificantes, pero tienen un impacto real. El esquema de la pista se utilizará para hacer coincidencias en la base de datos, y por eso los metadatos descriptivos corruptos tienden a romper las cosas. Asegúrate de revisar dos y tres veces los metadatos de la canción antes de enviarla — o establece un sistema de verificación en dos pasos. Una vez que la canción ya está publicada, corregir los errores tipográficos se vuelve muy problemático.
4. Sigue las directrices de metadatos
No se trata solo de qué pones, sino también de cómo formateas esos datos. La diferencia entre escribir el nombre de la canción como «Nombre de la Canción (Radio Edit)» y «Nombre de la Canción — Radio Edit» puede no parecer gran cosa, pero considera lo siguiente. Los datos musicales son como una habitación llena de espejos deformantes. Cada error viajará por la industria musical, amplificándose en su camino a través del laberinto de bases de datos. Incluso el menor error puede convertirse en un problema real para un artista, con canciones que acaban en la página equivocada de Spotify o regalías de ejecución que se pierden en el camino.
Para asegurarte de que no solo el contenido, sino también los formatos sean correctos, puedes utilizar directrices de metadatos. Sigue la guía de tu distribuidor — la mayoría son fáciles de seguir. Si las instrucciones de tu distribuidor no tienen todas las respuestas, consulta las directrices generales como la proporcionada por la Music Business Association.
5. Difunde el mensaje
Seguir esos pasos, por supuesto, no resolverá todos los problemas de metadatos de la industria. El problema en sí mismo es demasiado complicado, y solo podemos resolverlo si toda la industria musical está en la misma página. En ese sentido, el primer paso es concienciar a los profesionales de la música.
Los metadatos están en el núcleo de la industria musical, y ahora mismo están rotos. Los músicos pierden regalías. Los compositores e ingenieros no reciben el crédito que merecen. Los servicios de streaming han desarrollado algoritmos para asegurarse de que la parte superior del catálogo parezca limpia, pero una vez que te adentras en el «long tail», todo tipo de errores empiezan a caer por las grietas. Necesitamos empezar a avanzar hacia un sistema mejor.
En Soundcharts hacemos lo mejor que podemos con el sistema tal como está. Como plataforma de análisis de datos, tenemos que extraer datos de docenas de fuentes y bases de datos sucias. Luego, agregamos cuidadosamente los datos y cruzamos las etiquetas de metadatos para garantizar que cada posición en las listas, cada adición a una playlist de streaming, cada emisión de radio y cada mención en la prensa digital estén correctamente atribuidas. Mejoramos continuamente nuestros algoritmos de limpieza y coincidencia de metadatos, al tiempo que mantenemos un equipo de mantenimiento manual dedicado para abordar los problemas que se escapan. Eso es lo que nos convierte en la plataforma de análisis musical más limpia de la industria.

